Introduction
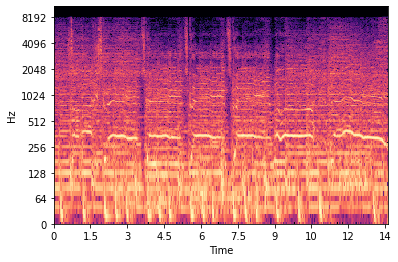
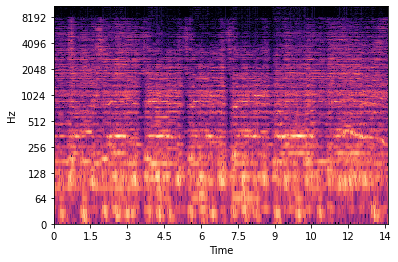
Stem splitting is the process of isolating different parts of a song into its individual pieces, typically vocal, percussive, and instrumental parts. This is useful for music creation, sampling, and remixing because it gives musicians the ability to create different aspects of music than what the original author intended. Our goal is to separate the vocals from the rest of a piece. Below is an example of a stem split of vocals and a comparison with the original piece:
Original Song
Vocals
The Applications of Machine Learning in Stem Splitting
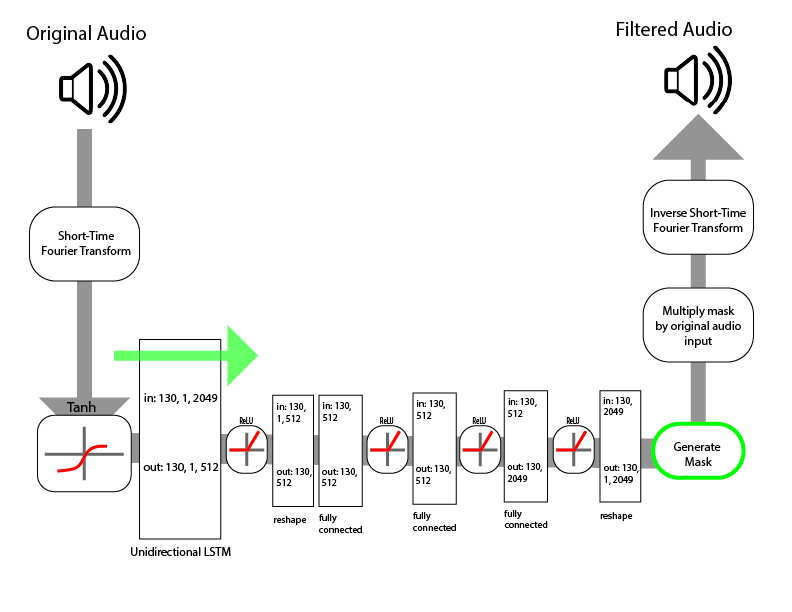
One of the main challenges of stem splitting is isolating the correct frequencies. For each instrument or voice, there are a set of undertones and overtones that give it its unique sound, otherwise known as timbre. To isolate a part from the rest of the song, we must correctly identify the overtones and undertones associated with the part.
In addition, the frequencies from each of these parts often overlap with each other, meaning separation is not as simple as recognizing that an instrument is playing and completely eliminating every frequency that the instrument plays. This complex set of problems makes this a well suited situation for a neural network because a neural network will learn to identify and isolate the frequencies associated with vocalization.
Designing a machine learning model which separates these parts is difficult, but not impossible. Many groups, such as SigSep and Google’s Magenta Research group, have successfully used LSTM neural networks to recognize patterns in vocals and instrumentation. Once the algorithm successfully isolates these frequencies, they can be filtered out and separated accordingly.
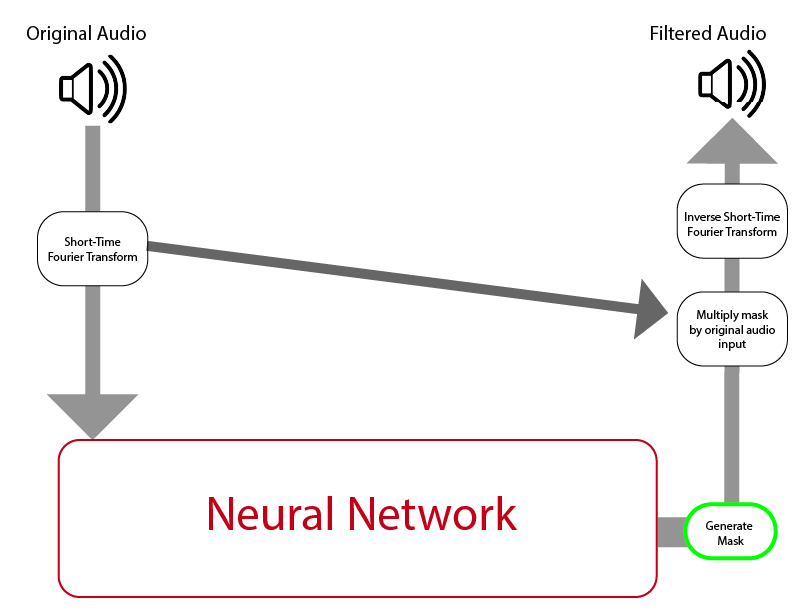
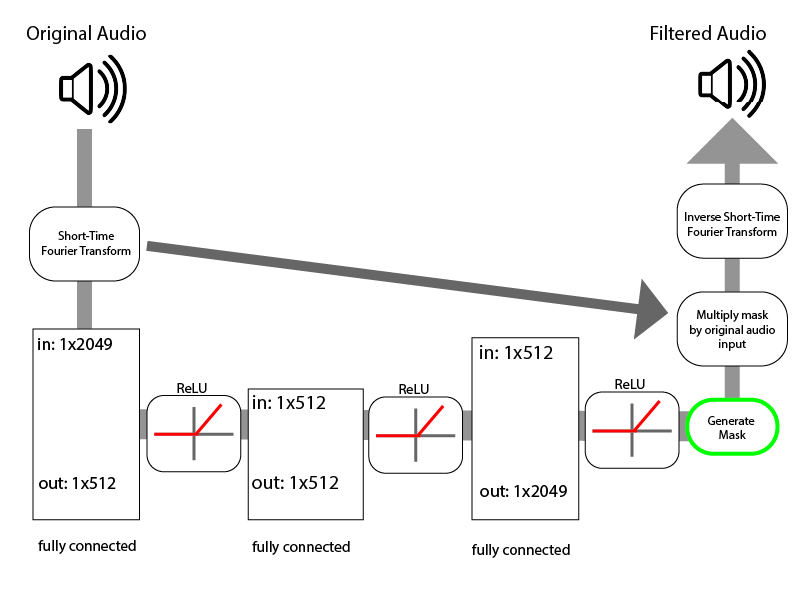
 Source:
Source: 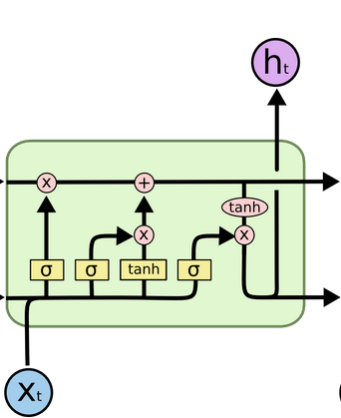 Source:
Source: